FAIR data – Ten simple rules to FAIRify your data
 |
In the fourth and final blog in this series Scibite’s Head of Ontologies, Jane Lomax, shares her top 10 simple rules to start and progress your FAIR data journey.

In the previous blogs in this series, we’ve explained why you need FAIR data, how ontologies help you develop a FAIR infrastructure, and how FAIR principles provide a means to get value from your data.
In the fourth and final blog in this series Scibite’s Head of Ontologies, Jane Lomax, shares her top 10 simple rules to start and progress your FAIR data journey.
1. Survey your ontology landscape
Rather than reinventing the wheel, it’s important to find out what’s already being used in your organization. This might be the pre-existing use of a public ontology or maybe a simple internal list of project or assay names. Once you’ve identified these, it’s important to make them accessible to everyone who needs to use them. Essentially: start with something useful, centralize it, and then build it out.
2. Decide on your metadata
While this might seem to be diving straight into the details, based on our experience with many ontology management projects, it’s important to get this right from the outset. Even if it’s only in a more general way, it’s easier to define how URIs (Uniform Resource Identifiers) should be structured to start with rather than have to change things later on.
relationships and annotation properties
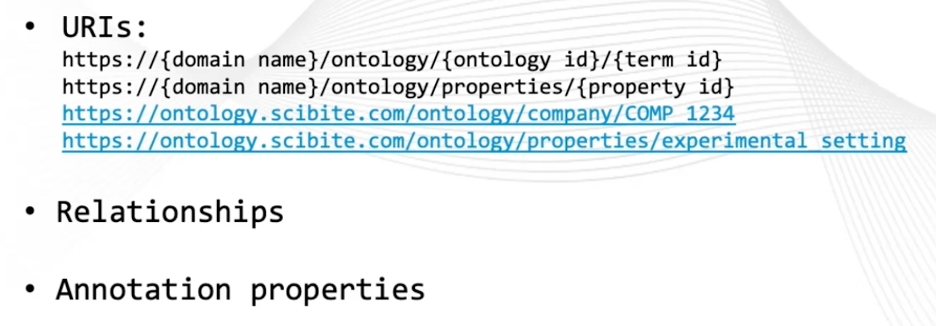
Figure 1: Examples of Structured URLs
Similarly, it’s good to define which relationships will be encapsulated in your ontology and which annotation properties to include, such as the definition, and synonyms to include.
If that sounds a bit daunting, don’t worry, we can provide expertise and guidance to get you started.
3. Rebuild, Reuse, Recycle
You should aim to only create new ontology terms if there’s no other option – it makes much more sense to use what is available already. While there might not be a perfect ontology in the public domain for your particular purpose, it’s possible to bring together the relevant parts of other ontologies to create an application ontology.
A great example of this is the Experimental Factor Ontology (EFO) which is designed for the annotation of Omics experiments. Rather than starting from scratch, EFO pulls in branches or classes from other ontologies, such as the Human Phenotype Ontology (HPO) and Gene Ontology (GO), and then, if needed, additional EFO-specific terms are layered on top.
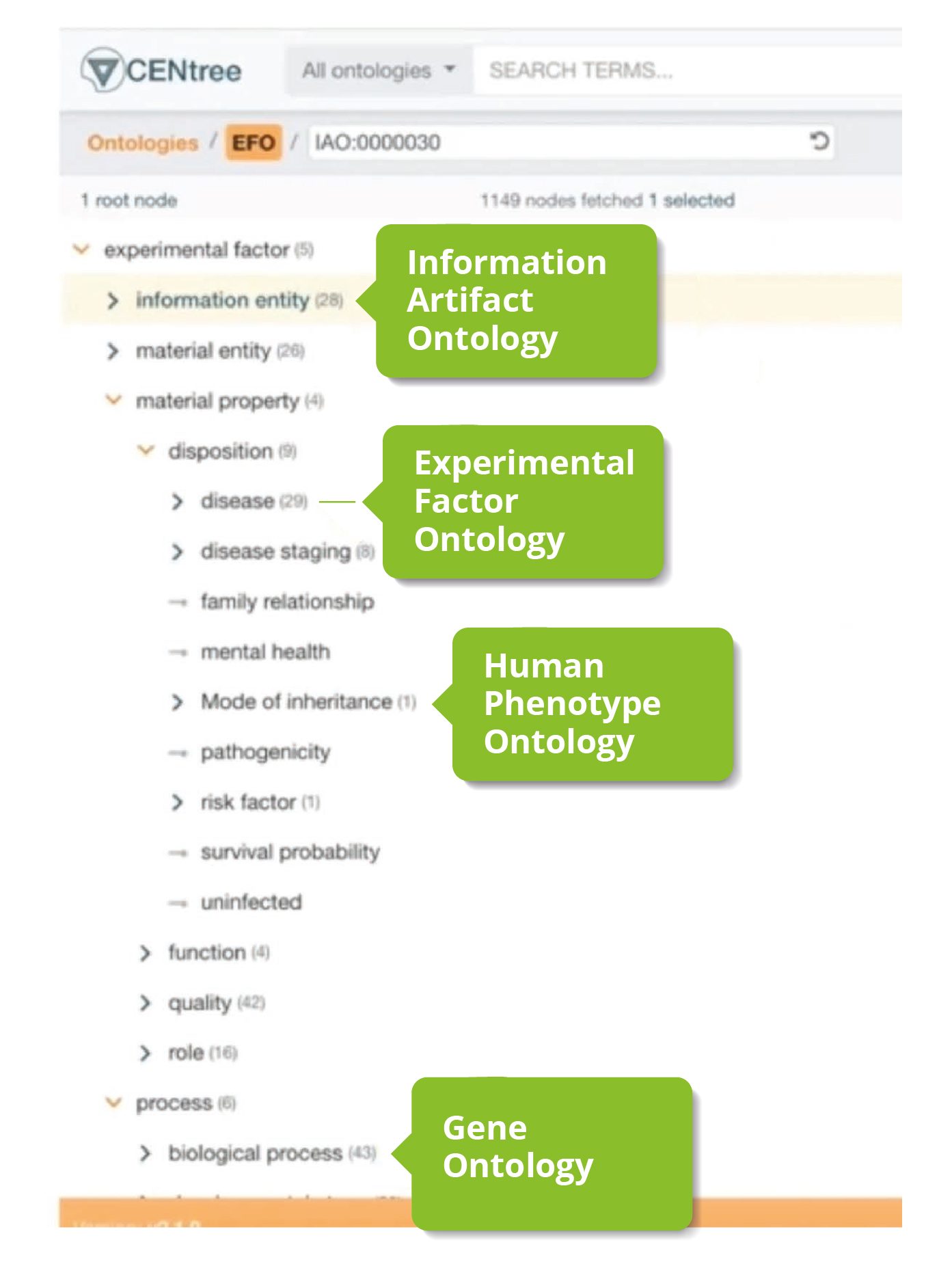
Figure 2: Rather than starting from scratch, the Experimental Factor Ontology brings together branches from other ontologies.
4. Map sparingly
Mapping between ontologies can be a complex undertaking. For example, it can be unclear if terms are equivalent if the ontologies being mapped were built with different use cases in mind. Any mapping will also need to be redone as the ontologies involved evolve, so it’s best to avoid it if you can.
However, sometimes ontology mapping is unavoidable. For example, if you are using multiple ontologies in use for the same domain, if you need to work with multiple standards required for regulatory purposes, or if you have data coming from external sources, such as CROs.
So, if you do have to map your ontology, then try to make sure you only have to do it once by mapping any internal ontologies to public ones: Our Workbench tool includes a mapping algorithm to simplify the mapping process.
Where a choice of ontologies exists, encourage your users to adopt a preferred ontology and use public standards where possible to leverage existing mappings.
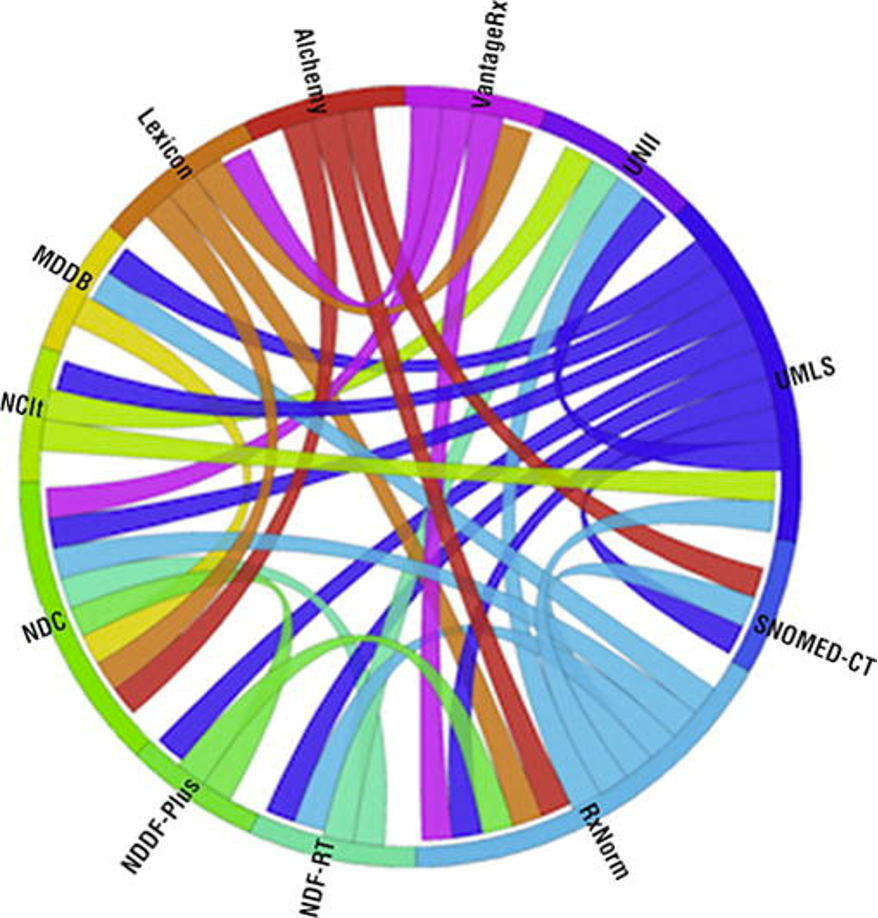
Figure 3: An illustration of ontologies containing medication information and connections between them.
5. Simplify your ontology selection
Related to the previous tip, try to keep to one ontology per domain if possible. Of course, life isn’t always that simple, but if you can at least limit the number of ontologies you’re working within a specific domain, then life will be a lot easier.
6. Find your FAIR champions
The organizations we work with that have the most success are the ones where there are a small group of tenacious people who understand the problem, have good organizational knowledge, and know who to talk to, such as the internal domain experts to consult with. These people don’t necessarily need to be ontology experts but can be the critical ingredient for the successful rollout of FAIR projects across the organization.
“Never doubt that a small group of thoughtful,
committed citizens can change the world;
indeed, it’s the only thing that ever has.”
Margaret Mead, Anthropologist
7. Start small and iterate…
Make no mistake – FAIR is a big project. It’s a journey that is never finished, so it can sometimes seem to be an insurmountable problem – where do you even start? The key is breaking it down and tackling one thing at a time, whether that is one use case, one group, or one problem.
Whichever you choose, use the first one as a prototype, refine the approach based on your experience, and repeat to address the next use case, and so on and so forth.
8. …But start!
Don’t let the potential size of the problem put you off or wait for everything to be perfect… otherwise you’ll be the victim of ‘analysis paralysis’. Find your key use cases and get started – try things out and see what works and what doesn’t.
“A little semantics goes a long way.”
Jim Hendler, Semantic Web Expert
You don’t have to be creating huge ontologies, just start somewhere – consolidate the relevant lists and put them somewhere central. Then educate people – explain how and why the ontologies will help and let them know where to find them.
9. Find the business value
It’s not always easy to demonstrate the short-term business value for FAIR projects as the major impact is often felt downstream or by doing things that aren’t possible today. FAIR is a long-term investment with common benefits including saving time searching for information and gaining more and deeper insights from existing data, through to providing the foundation to enable the organisation to adopt new technologies such as Artificial Intelligence successfully.
10. Empower your Subject Matter Experts
Subject Matter Experts (SMEs) have a deep understanding of their field and will want to see it represented correctly. Involve them in the process of modelling their domain and take the time to crystallise their knowledge and harness their enthusiasm.
Summary
As we’ve seen over the course of this blog series, the FAIR principles should be at the heart of an effective data strategy for any pharmaceutical company. We’ve also described how ontologies provide the key to being FAIR, and how FAIR enables you to get more value from your data.
Contact us at to find out how our expertise and technology can help expedite your FAIR data journey.
About Jane Lomax
Head of Ontologies, SciBite
Jane leads the development of SciBite’s vocabularies and ontology services. With a Ph.D. in Genetics from Cambridge University and 15 years of experience working with biomedical ontologies, including at the EBI and Sanger Institute, she focussed on bioinformatics and developing biomedical ontologies. She has published over 35 scientific papers, mainly in ontology development.
Other articles by Jane
1. [Webinar] Introduction to ontologies Watch on demand.
2. [Blog] Why do you need FAIR data? Read more.
3. [Blog] The key to being FAIR read more.
4. [Blog] Using ontologies to unlock the full potential of your scientific data – Part 1 read more.
5. [Blog] How biomedical ontologies are unlocking the full potential of biomedical data. Read more.
Related articles
-

The key to being FAIR

In our previous blog, we explained why FAIR data is important not only for biotech and pharmaceutical companies but also for their partners. Here we describe how ontologies are the key to having the richly described metadata that is at the heart of making data FAIR. Let’s explore how ontologies help with each aspect of the FAIR data principles…
Read -

FAIR as a means to get more value from your data
In this blog, we’ll explore a selection of the many ways organizations can leverage the rapid developments in data discovery, machine learning, and data mining to release value from this asset.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.