FAIR as a means to get more value from your data
 |
In this blog, we’ll explore a selection of the many ways organizations can leverage the rapid developments in data discovery, machine learning, and data mining to release value from this asset.

Introduction
Most pharmaceutical companies are unable to realize the true value of the wealth of data at their disposal. A large amount of R&D data generated within a pharmaceutical company is inaccessible because it is unstructured free text, or is stored in disconnected silos. This presents a barrier to embracing new technologies, such as Artificial Intelligence (AI) and Machine Learning (ML).
According to the Pistoia Alliance, “Maybe the biggest hindrance to using AI/ML effectively is both the volume and quality of data that exists. The models being built will only be as good as the data that has been used… As an industry, are we being overly optimistic and simplistic about the quality of data that we are feeding our smart new AI/ML pipelines?”. Similarly, in a 2017 survey of over 16,700 data scientists, the most cited challenge to undertaking machine learning was “dirty data.”
In the previous blogs in this series, we’ve established that using ontologies to apply FAIR principles results in the clean, ‘self-describing’, machine-readable data necessary for advanced computational techniques to be effective and deliver accurate and true outputs. Essentially turning data into an asset.
In this blog, we’ll explore a selection of the many ways organizations can leverage the rapid developments in data discovery, machine learning, and data mining to release value from this asset.
Using FAIR knowledge graphs to identify new relationships
Knowledge graphs provide essential context for many AI applications. Building an effective knowledge graph is critically dependent on the source data sets being interoperable.
The semantic enrichment used to deliver FAIR data facilitates cross-linking between equivalent concepts described by different data sources, even if the original authors used different names for the same thing.
For example, as illustrated below, several facts are known about Target C, but the data is stored in three different data sources, each of which uses a different synonym, making it challenging to identify connections. With FAIR data, all 3 synonyms can be understood as the same thing and aligned to a single term, thus providing the glue to make connections between the data sets which can reveal otherwise hidden associations and relationships. This has a wide range of applications, such as drug repositioning.
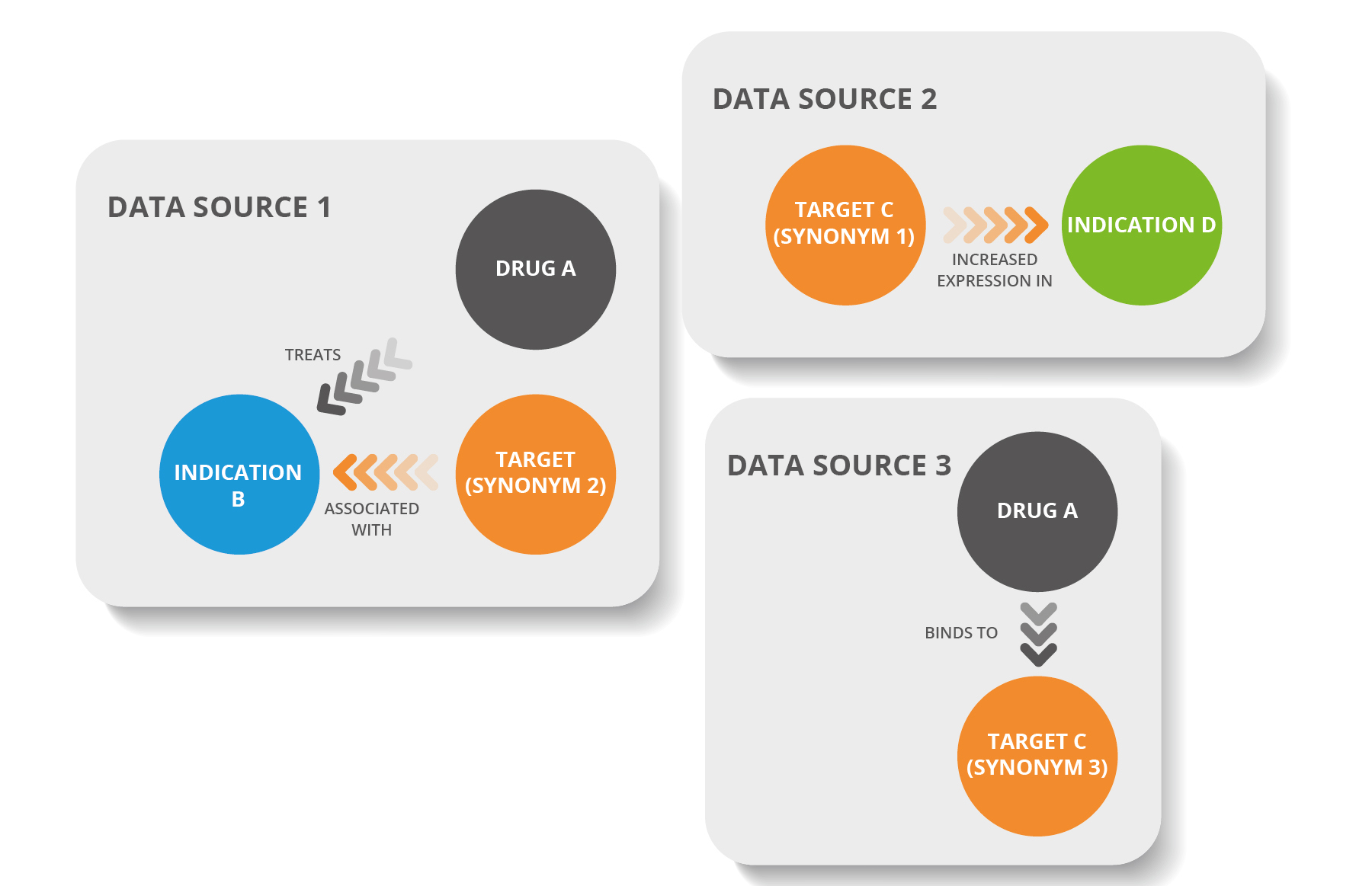
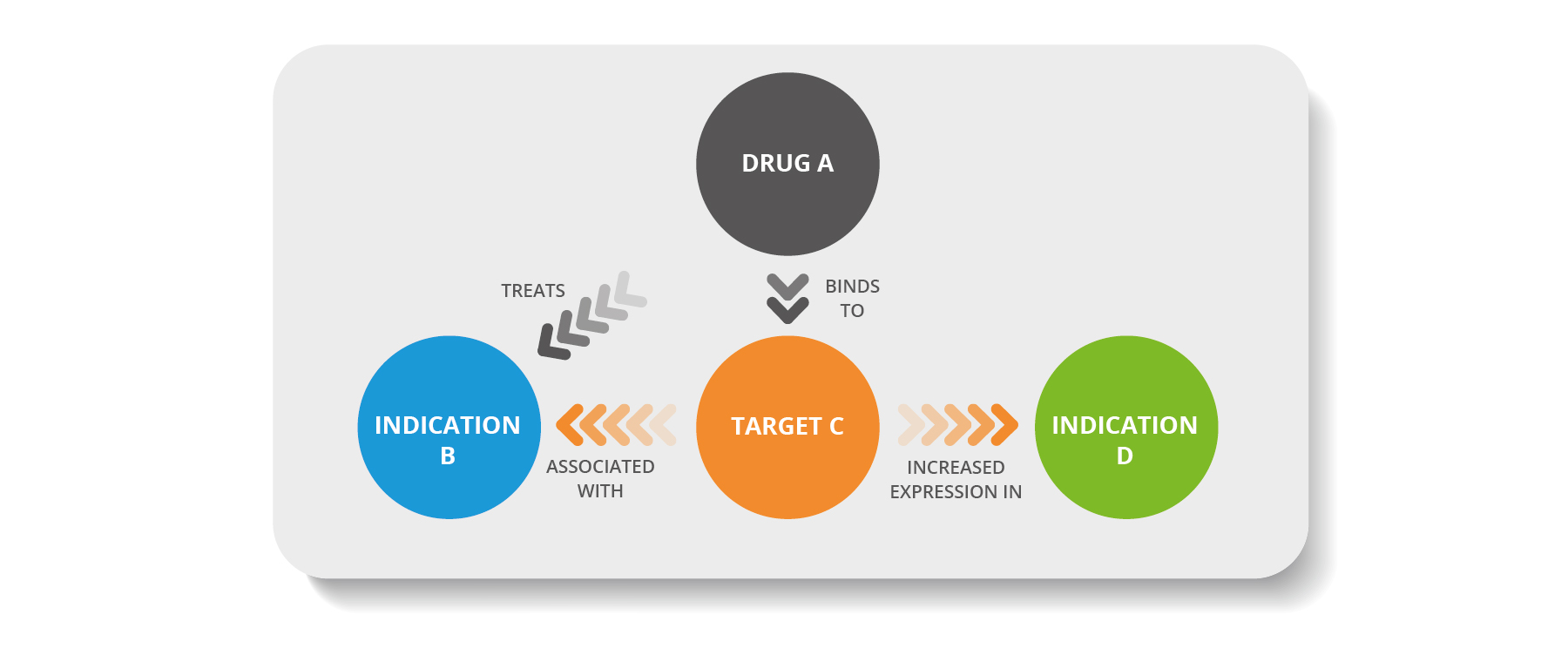
Figure 1: Where different data sources use different synonyms for the same entity, it can be challenging to connect them (Upper Image); FAIR data enables connections to be made and represented using a knowledge graph (Lower Image).
FAIR data as an enabler of effective AI/ML
Despite enormous advances in next-generation computational methods, such as Machine Learning and Artificial Intelligence (AI), most still struggle to deal with the complexity, ambiguity, and variability of unstructured scientific language.
For example, ambiguity can lead to a term being mistaken as the wrong type of entity. For instance, ‘ALS’ is an abbreviation for Amyotrophic Lateral Sclerosis. However, it is also used as a synonym for the gene ‘Insulin-Like Growth Factor Binding Protein Acid Labile Subunit’ (IGFALS).
FAIR data helps to address this problem. By removing ambiguity, a machine learning algorithm will be able to exclude literature related to IGFALS from a model for the disease ALS, and avoid making an incorrect link between ALS and insulin signaling with potentially dangerous consequences.
But it doesn’t end there. Without ontologies, an AI model needs to learn everything from scratch. Imagine going into a library and trying to find a book without some form of classification or indexing to guide you to its likely location. That’s why the Dewey Decimal system was developed – to help people find the right information faster.
Ontologies serve a similar purpose in science. Since they encapsulate a common model of knowledge associated with a given domain and establish hierarchical relationships between terms, they can give AI a ‘head start.’ For example, a machine learning algorithm doesn’t need to be ‘taught’ that Crohn’s is an inflammatory disease if this relationship is already encapsulated in an ontology.
FAIR data not only enables more effective training of AI/ML models, but FAIRification also provides the clean, high-quality data inputs required for AI/ML to deliver accurate and reliable results when applied to a range of use cases, such as document classification and intelligent search.
Intelligent search enabled by FAIR data
As described in the previous blog in this series, semantic enrichment increases the Findability of data, resulting in greater search recall, accuracy, and precision, and also enables scientists to answer more complex questions using ontology-based queries.
But FAIR data enables you to go even further. Deep learning enables the modern search engines we use in our everyday lives to reliably recognize why we are asking a question, something otherwise known as ‘intent.’ This can be applied to the scientific domain too – by combining deep learning with semantic search, SciBite Search enables scientists to use natural language scientific queries ranging from questions that have a ‘yes/no’ answer to those that require aggregation of information, such as:
- Is fingolimod an immunomodulatory drug?
- What are the known modulators of sphingosine-1-phosphate receptors?
- What is the top-mentioned drug for multiple sclerosis?
- What are the top 5 indications for fingolimod?
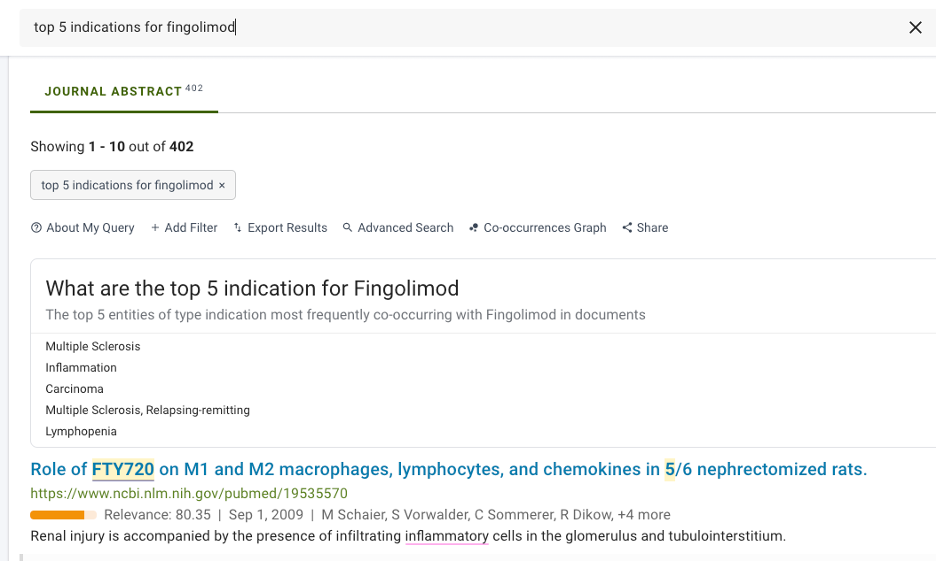
Figure 2: SciBite Search enables users to answer complex questions easily.
This also enables users to ask questions about more complex relationships, such as “Does fingolimod have any known side effects due to interactions with other drugs?”.
Summary
By applying the FAIR principles, data becomes an asset. When an organization has FAIR data, they have the opportunity to employ novel technology and advanced computational techniques to release significant value from it.
In the final blog in this series, we’ll share ten simple rules to FAIRify your data. In the meantime, contact us to find out how we can help you on your FAIR data journey.
About Jane Lomax
Head of Ontologies, SciBite
Jane leads the development of SciBite’s vocabularies and ontology services. With a Ph.D. in Genetics from Cambridge University and 15 years of experience working with biomedical ontologies, including at the EBI and Sanger Institute, she focussed on bioinformatics and developing biomedical ontologies. She has published over 35 scientific papers, mainly in ontology development.
Other articles by Jane
1. [Webinar] Introduction to ontologies Watch on demand.
2. [Blog] Why do you need FAIR data? Read more.
3. [Blog] A day with the FAIRplus project: Implementing FAIR data principles read more.
4. [Blog] Using ontologies to unlock the full potential of your scientific data – Part 1 read more.
5. [Blog] How biomedical ontologies are unlocking the full potential of biomedical data. Read more.
Related articles
-

Why do you need FAIR data?

For many organizations, the idea of adopting FAIR can be confusing and daunting. Over the coming weeks, we’ll present a series of blogs to help demystify FAIR. In this series, we’ll cover topics including how ontologies provide the key to being FAIR, and how FAIR enables you to get more value from your data.
Read -

The key to being FAIR
In our previous blog, we explained why FAIR data is important not only for biotech and pharmaceutical companies but also for their partners. Here we describe how ontologies are the key to having the richly described metadata that is at the heart of making data FAIR. Let’s explore how ontologies help with each aspect of the FAIR data principles…
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.