The key to being FAIR
 |
In our previous blog, we explained why FAIR data is important not only for biotech and pharmaceutical companies but also for their partners. Here we describe how ontologies are the key to having the richly described metadata that is at the heart of making data FAIR. Let’s explore how ontologies help with each aspect of the FAIR data principles…

How can ontologies help me find information?
An increasing awareness of the importance of FAIR has also highlighted the limitations of many traditional scientific tools when it comes to enabling data to be found and reused more readily. For example, most scientific applications are limited to keyword and metadata searches – a search for the Alzheimer’s related gene, PSEN1, would miss references to synonyms such as Presenilin-1, AD3 and PSNL1.

Figure 1: Most search tools miss synonyms of search terms of interest.
Semantic enrichment is the use of ontologies to assign a unique meaning, description, and unique identifier (in the form of a Uniform Resource Identifier or URI) to scientific terms. The result is greater recall, accuracy, and precision, ensuring that all relevant data is found, regardless of which synonym is used as the search term.
With semantically enriched data, scientists can also answer more complex questions using concept-type searches (e.g., find any mentions of a target, indication, etc. of interest) and ontology-based queries (e.g., find any references to a ‘type’ of entity such as a drug).
Examples of questions that can be rapidly answered with semantically enriched data
- Find all experiments for a specific target across the organization, regardless of which synonym was used by the author of the experiment.
- Which projects are investigating potential biological therapeutics?
- Which targets have we studied that are associated with inflammatory disorders?
- Which diseases have we studied for both a target of interest and other targets in the same class, and what were the outcomes?
- Which pre-clinical studies have utilised a specified rodent model?
How do ontologies help to make data more accessible?
In the context of FAIR, accessibility is all about good data governance. Data is considered accessible when there is a combination of i) a good standard protocol for retrieving the data, ii) users know how to access it, and iii) metadata are available even when the full dataset might not be.
This latter point is where ontologies are particularly helpful. When data isn’t well described, it can be difficult or impossible to be confident about whether it is fit for an intended purpose without a detailed review of accompanying documentation or even contacting the author.
When data is accompanied by a comprehensive set of experimental metadata, such as species, cell line, method, etc., each aligned with an ontology, not only is it easier to find relevant data sets, but it is also possible to determine the relevance of a given dataset. For example, to perform an analysis across multiple gene expression studies, knowing the cell line that was used as the basis for a study can help determine if it’s suitable to include in a comparison or not.
How do ontologies help to make data interoperable?
When different data sources don’t use a common language, it makes it difficult to combine or integrate the data within them. For example, if a gene expression database contains a reference to the Type II Diabetes-related gene, ABCC8, while a database of compounds and their targets refers to a synonym of ABCC8, such as ‘SUR1’ or ‘MRP8’, then it can be a challenge to make connections between them.
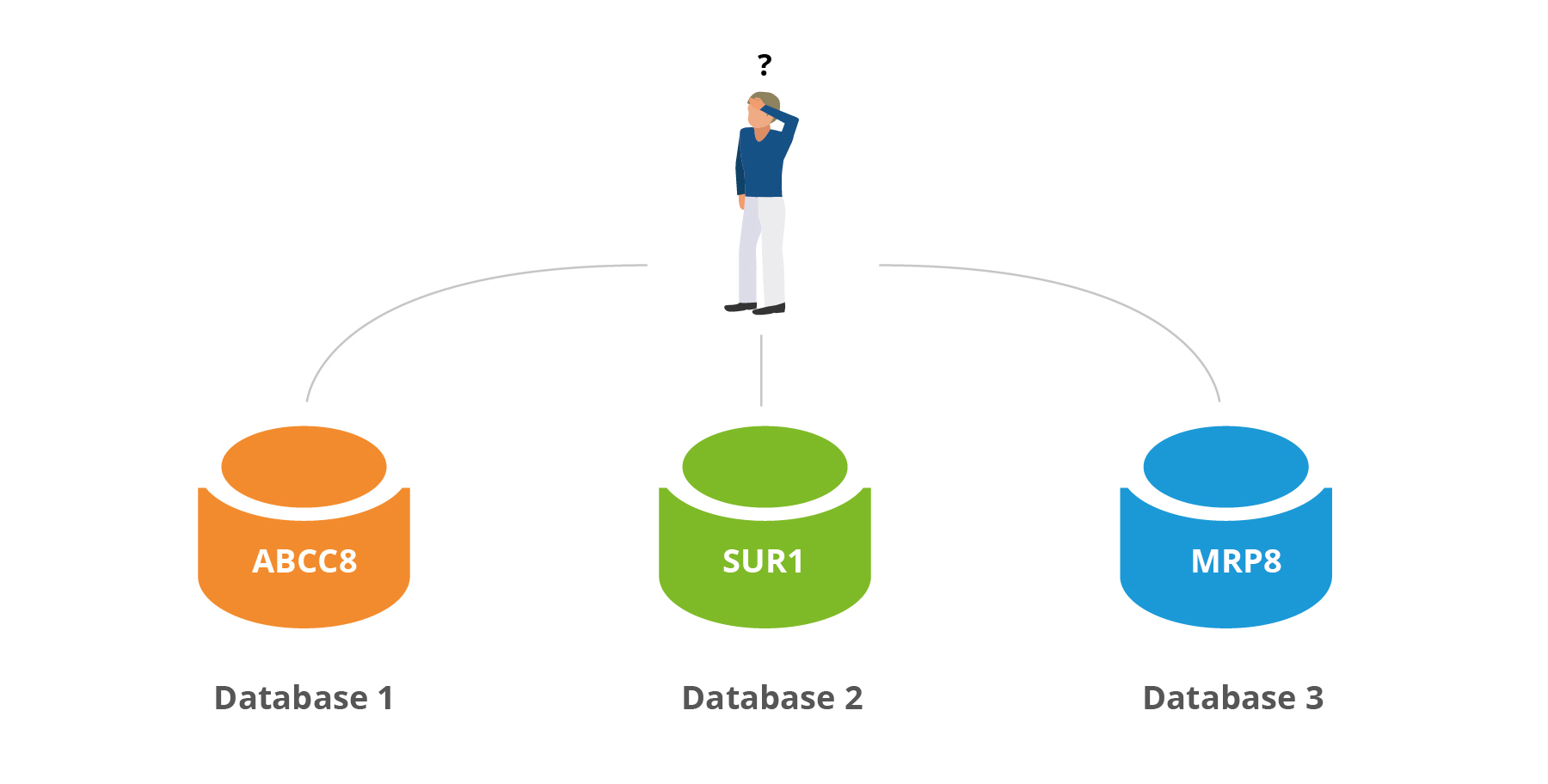
Figure 2: Data integration is challenging when different data sources don’t use the same language.
Ontologies enable you to align your data with public standards, such as ChEMBL (chemical entities), GO (Gene Ontology), and MeSH (Medical Subject Headings). Using a common language as a ‘semantic glue’ makes it easier to:
- Ask questions across data sources that would have otherwise been time-consuming or impossible to answer.
- Gain a holistic view of everything that is known, both internally and externally, about a topic of interest, such as a compound, target, or disease.
- Identify linkages or connections that might have otherwise remained hidden.
- Collaborate both between sites and with partners, such as CROs.
When trying to make data interoperable, the source of ontologies is a key consideration, as the use of a proprietary ontology results in reliance on a specific vendor. While our expert team of ontologists enriches our VOCabs to ensure they have the comprehensive synonym coverage needed for effective text analytics, we always ensure they are aligned with public standards. Similarly, SciBite’s ontology management platform, CENtree, uses open standards, ensuring there is no ‘lock-in’ to proprietary language or formats when managing ontologies. This ensures that data enriched by SciBite is open and transportable from system to system, which is fundamental to ensuring it is interoperable.
How do ontologies help to make data more reusable?
Data creators often overlook re-using data beyond its original purpose, which creates a problem that can quickly get out of control. This is the main reason why data scientists spend so much time as ‘data janitors’ collecting, cleansing, formatting, and linking data, instead of actually analyzing it.
In many respects, addressing the first three elements of FAIR provides the foundation for reusability – if data is findable, accessible, and interoperable, then it is far more likely that it can be reused effectively.
When existing data can be shared and widely understood, it can be used to answer new questions. For example, a scientist may conduct a study to determine the stability profile of a molecule of interest. When the resulting data is managed according to FAIR principles, other people within the organization will be able to find and integrate it with data from studies from both across the company and from data in the scientific literature to identify trends and correlations.
Ultimately, when data is reusable, organizations can avoid having to recreate the same or similar data for different purposes, eliminating unnecessary re-invention.
Managing ontologies effectively
Given the pivotal role of ontologies in making data FAIR, it’s important to manage them effectively. For example, data scientists often need to perform different analyses with the same ontologies, so they need to be managed carefully and centrally to ensure that they can be used consistently.
SciBite’s ontology management platform, CENtree, provides a single location to manage ontologies that are used across multiple different systems, eliminating the need to update each system individually. Subject matter experts can easily contribute to keeping things current and augment public ontologies with proprietary information, such as project codes and IDs used to track materials such as compounds and cell lines, to create a single, authoritative, universally applied terminology that represents evolving scientific language.
Summary
As you can see, ontologies are at the heart of making data Findable, Accessible, Interoperable, and Reusable. In the next blog in this series, we’ll be describing how FAIR enables you to extract more value from your data.
In the meantime, contact us at [email protected] to find out how we can help you on your FAIR data journey.
About Jane Lomax
Head of Ontologies, SciBite
Jane leads the development of SciBite’s vocabularies and ontology services. With a Ph.D. in Genetics from Cambridge University and 15 years of experience working with biomedical ontologies, including at the EBI and Sanger Institute, she focussed on bioinformatics and developing biomedical ontologies. She has published over 35 scientific papers, mainly in ontology development.
Other articles by Jane
1. [Webinar] Introduction to ontologies Watch on demand.
2. [Blog] Why do you need FAIR data? read more.
3. [Blog] A day with the FAIRplus project: Implementing FAIR data principles read more.
4. [Blog] Using ontologies to unlock the full potential of your scientific data – Part 1 read more.
5. [Blog] How biomedical ontologies are unlocking the full potential of biomedical data read more.
Related articles
-

Why do you need FAIR data?

For many organizations, the idea of adopting FAIR can be confusing and daunting. Over the coming weeks, we’ll present a series of blogs to help demystify FAIR. In this series, we’ll cover topics including how ontologies provide the key to being FAIR, and how FAIR enables you to get more value from your data.
Read -

Large language models (LLMs) and search; it’s a FAIR game

Large language models (LLMs) have limitations when applied to search due to their inability to distinguish between fact and fiction, potential privacy concerns, and provenance issues. LLMs can, however, support search when used in conjunction with FAIR data and could even support the democratisation of data, if used correctly…
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.