Ontology mapping:
Finding the right automated approach
 |
Ontologies are crucial for unlocking information. However, similar types have been created for different needs, reducing their interoperability. In this blog, we look at some of the automated approaches for large-volume ontology mapping.

Ontology mapping: Finding the right automated approach
Ontologies are key in how we share common understandings, do research, and build technologies. Critical for knowledge integration is the ability to reconcile terms from one ontology to related concepts in other ontologies. We previously looked at some of the challenges and approaches of doing this. In this post, we’ll provide a high-level overview of some of the automated methods that have been developed which are enabling the rapid connection of high numbers of ontology terms.
Automated approaches to ontology mappings
Performing ontology alignments can be complex, often requiring subject matter expertise to recognize context and nuance. Several unsupervised and semi-supervised automated approaches which scale up mappings have been developed. These can broadly be classified into rules-based and machine learning techniques.
Rules-based
Lexical mapping tools, including the open-source Agreement Maker Light (AML)1 or Large-Scale Ontology Matching System (LSMatch)2, use algorithms to detect similarities between labels and synonyms of corresponding ontologies. Other rules-based approaches include LogMap3 which infer or negate mappings by comparing ontology structures and relationships. Whilst these approaches can achieve high levels of precision, they often work best when additional information is already available about a concept (synonyms, logical descriptions, existing classification etc..), something that is often missing from flat lists or simple vocabularies.
Machine learning
Machine learning has been used to identify relatedness between concepts. This is particularly useful for lists which lack ontology structure and metadata. These techniques include Word2Vec, which uses word embeddings4, as well as language models like BERTmap, a fine-tuned version of BERT for mapping predictions coupled with analysis of ontology structure and logic5.
Combining different rules-based or machine learning mapping techniques is yielding more accurate mappings. In a recent paper, the large language model (LLM), MapperGPT was used in a post processing step with a high-recall simple lexical algorithm. When deployed this way, researchers were able to eliminate the technology and financial overhead of using a GPT model to singularly map all concepts, by instead deploying it to isolate and remove false positives6.
Precision and Recall
The performance of classification models and mappings can be measured by considering their precision and recall. Precision can be seen as a measure of quality, whilst recall as a measure of quantity. Higher precision means that the algorithm returns more relevant results than irrelevant ones, and high recall means that an algorithm returns most of the relevant results (whether or not irrelevant ones are also returned). Accuracy, Precision, and Recall — Never Forget Again!7 is an excellent explainer.
Comparing apples with apples: Assessing automated ontology mappings
In order to accurately assess the performance of different ontology mapping approaches, researchers can compare their results to standard datasets produced by the Ontology Alignment Evaluation Initiative (OAEI)8. These gold standards, which are published each year, are organized by tracks, for example, the anatomy track is a real-world set of mappings between the Mouse Anatomy (2744 classes) and the NCI Thesaurus (3304 classes) describing the human anatomy. The OAEI also publishes its results allowing data scientists to compare their models against other industry models.
Challenges with automated mapping
Whilst there is a plethora of approaches available that generate large numbers of “likely” alignments, automated ontology mapping is not without its challenges. These include:
- Predictive mapping algorithms are not 100% accurate – Some level of human curation is required. For example, lexical matching alone can miss some of the subtleties often found when considering similar concepts within life science vocabularies e.g. indication vs phenotype vs adverse events. The trick is to find the right level of “human in the loop”!
- Difficulty setting up and installing tools – Getting started can be mind-boggling and perhaps cumbersome, particularly if you just want to align a short list to public standard
- Usability – Creating and viewing mappings isn’t always simple.
- Poor performance over large terminologies – For larger vocabularies, for example, ~100k terms and potentially 1M synonyms, it can be difficult to set up the right infrastructure to create and store mappings.
- Lack of flexibility – It’s not always easy to fine-tune mapping approaches for example, depending on your data, you may want to lose some precision to explore better recall.
- Versioning and maintenance missing – Mappings that are produced using various techniques within the public domain are often not versioned or kept up to date.
SciBite’s approach to ontology mapping
At SciBite, we’ve developed Workbench, a simple, user-friendly tool that allows users to map ontologies. Workbench connects concepts using TERMite, SciBite’s named entity recognition engine, and and over 80 core SciBite vocabularies, providing comprehensive coverage of the biomedical domain and containing >20 million synonyms..
A user would begin by adding in the source ontology, and then selecting the target ontology they wish to map to. In the following example, (see Figure 1) terms from the source ontology, Mouse Anatomy (MA) are being mapped to human anatomy terms within the target National Cancer Institute (NCIt) ontology.
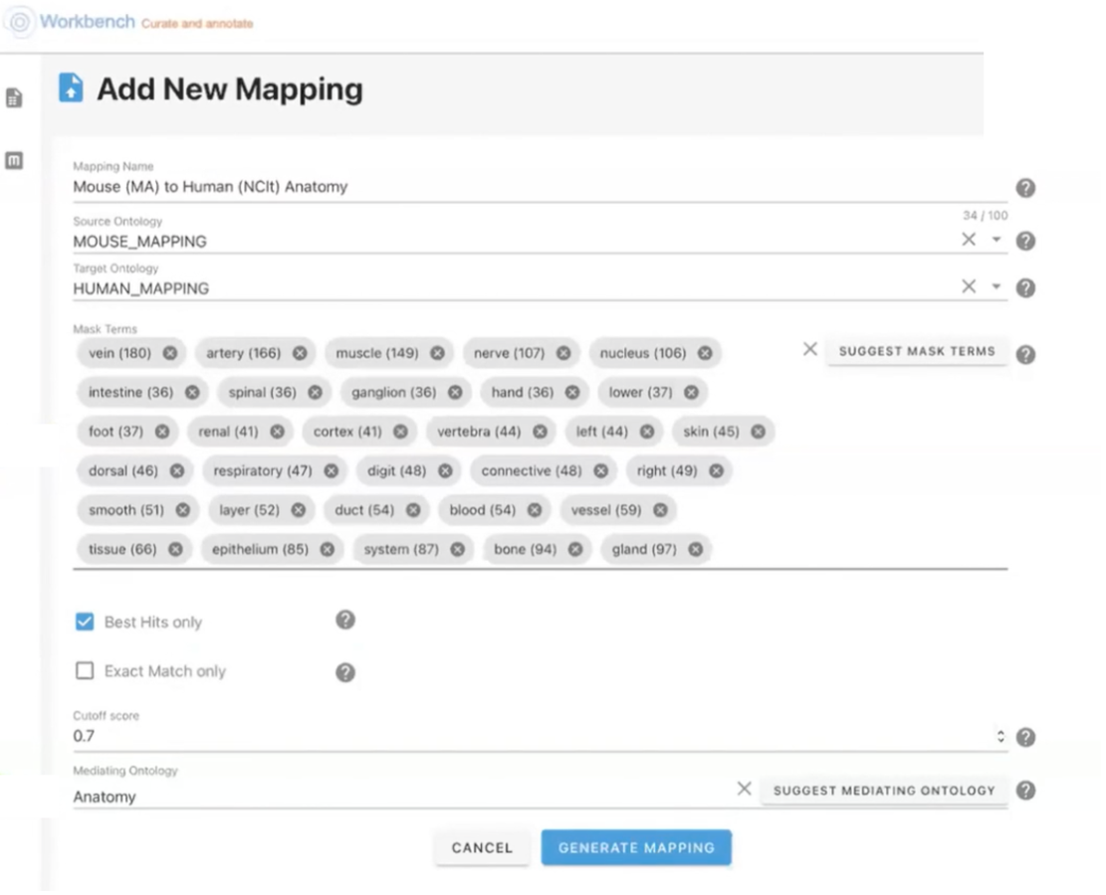
Figure 1: Selecting the source and target ontologies.
Workbench also includes some options to control the specificity of suggested ontology mappings. It’s possible to use mask terms, which effectively allows users to exclude certain words from the string similarity algorithm that may be considered noisy. For example, the terms disease or system may be disregarded if they are found to occur within multiple concepts within the source and target ontologies. Users are also able to control the suggested mapping relationships (exact, broad, and none) or the similarity scoring between mapped concepts.
How ontology mappings in Workbench work
Workbench uses a string similarity algorithm that calculates a similarity score and an ambiguity score. A lower score is created if a term within the source ontology matches multiple terms within the target ontology. If exact matches aren’t observed, Workbench also includes a substring match (e.g., parent-child) score.
We’re also able to use SciBite’s extensive vocabularies to suggest specific vocabularies that can act as mediators to generate mappings if there are no direct matches between source and target concepts or synonyms. In the following example (see Figure 2), it would not be possible to map the Mouse Anatomy term (MA:0000254) to the National Cancer Institute Thesaurus (NCI:C32164) term as there are no direct matches between their concepts or synonyms. However, Workbench can produce a mapping based on SciBite’s Anatomy vocabulary, which contains the related Auditory Ossicle and auditory bone terms to connect the MA and NCI ontologies.

Figure 2: Using SciBite’s mediating vocabularies.
Viewing ontology mappings in Workbench
Mappings generated in Workbench are displayed within a simple table (see Figure 3). The source concepts and their corresponding mapped target terms are presented in rows, along with the semantic relationship, similarity score and the common or “matched” term between source and target. Within Workbench, users have the option of reviewing specific mappings which can be saved for future ontology alignments.
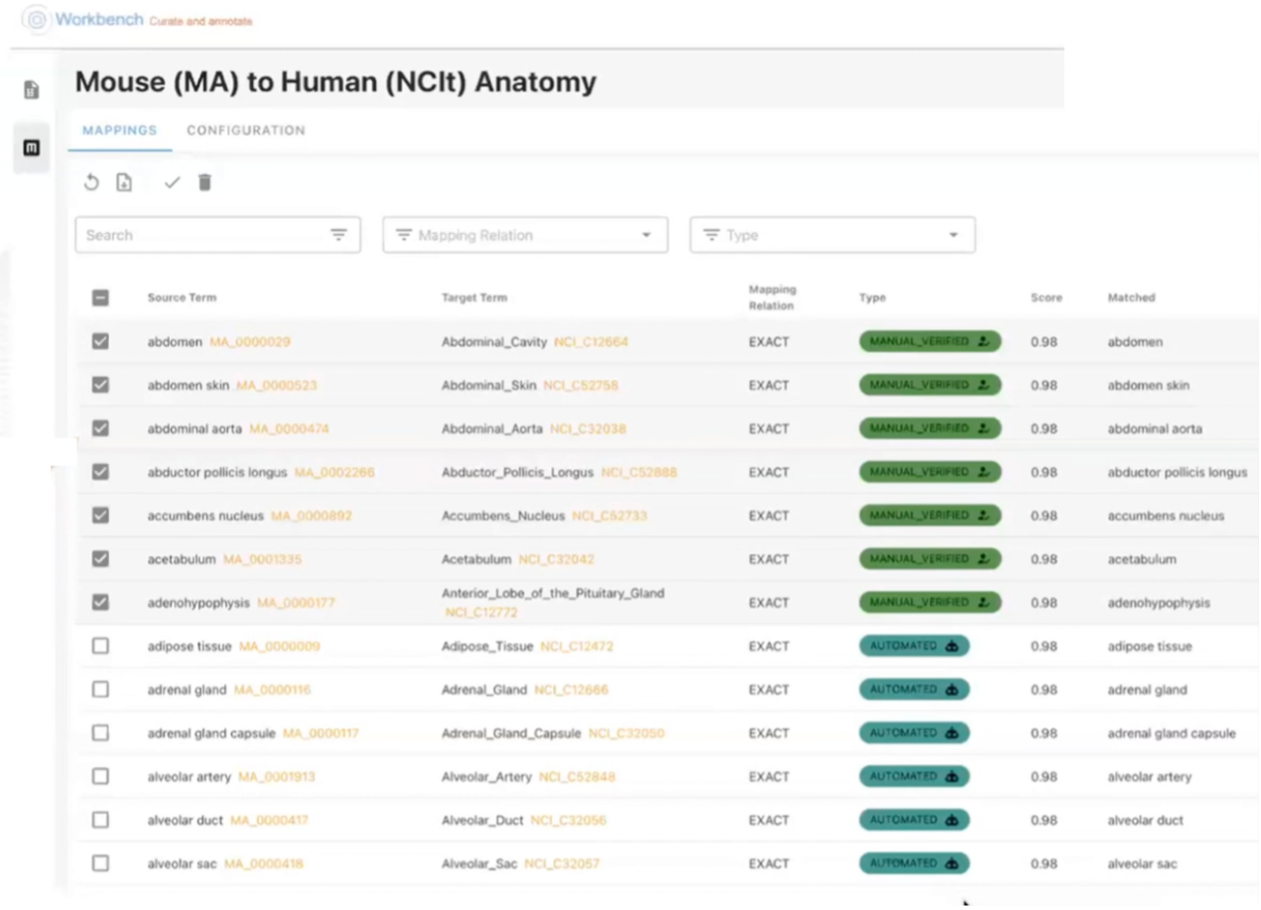
Figure 3: View ontology mappings in Workbench.
So, what’s next for Workbench…
SciBite recognizes the importance of providing biocurators with a simple tool for rapidly and accurately mapping ontologies. We are keen to extend the mapping algorithm to use combined rules-based and machine-learning approaches, as well as SciBite’s versioned, maintained, and customizable mapping datasets to support mapping predictions.
We’d love to hear your thoughts. What automated approaches do you use to map your ontologies, what work well and what are your challenges? To share your responses or for more information about our ontology mapping datasets or Workbench, please get in touch.
References
- D. Faria et al., The Agreement MakerLight Ontology Matching System, Published in OTM Conferences 9 September 2013, Computer Science, Medicine
- A. Sharma et al., LSMatch and LSMatch-Multilingual Results for OAEI 2022, CEUR Workshop Proceedings, 3324, 10. https://ceur-ws.org/Vol-3324/oaei22_paper10.pdf
- E. Harrow, et al., 2017, Matching disease and phenotype ontologies in the ontology alignment evaluation initiative. Journal of Biomedical Statistics, 8, 55. DOI: 10.1186/s13326-017-0162-9
- N. Teslya, et al., Matching Ontologies with Word2Vec-Based Neural Network. In: S. Misra et al.Computational Science and Its Applications – ICCSA 2019. ICCSA 2019. Lecture Notes in Computer Science, vol 11619. Springer, Cham. https://doi.org/10.1007/978-3-030-24289-3_55
- Y. He et al., BERTMap: A BERT-Based Ontology Alignment System, Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36, 5684 – 5691. DOI: 10.1609/aaai.v36i5.20510
- Matentzoglu et al., 2023, MapperGPT: Large Language Models for Linking and Mapping Entities,Computation and Language, arXiv:2310.03666
- K. Fessel, Accuracy, Precision, and Recall — Never Forget Again! http://kimberlyfessel.com/mathematics/data/accuracy-precision-recall/
- Ontology Alignment Evaluation Initiative, http://oaei.ontologymatching.org
About Andy Balfe
Product manager, SciBite
Andy Balfe received his BSc and PhD in organic chemistry from the University of East Anglia. He coordinates the delivery of innovative projects across SciBite’s product suite.
View LinkedIn profile
Other articles by Andy
1. Ontology mapping: Advancing data interoperability Read article
2. SciBite launches Workbench – Taking the effort out of tabular data curation Read article
3. Harnessing our latest VOCab: Emtree read article
4. What’s in our 6.5.2 TERMite / VOCabs release read article
Related articles
-

Ontology mapping:
Advancing data interoperability
Ontologies are crucial in unlocking information that helps fuel innovation. However, similar ontologies have emerged within the same domain, making it difficult for researchers to identify the right ontology to choose. Here we look at some of the complexities and strategies for handling ontology mappings.
Read -

SciBite launches Workbench –
Taking the effort out of tabular data curationSciBite, a leading provider of semantic technology solutions, has today announced the launch of Workbench, a structured data annotation tool that simplifies the process of curating data to terminology and ontology standards.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.