Sprinkling a little semantic enrichment into your data catalog
This blog focuses on the use and value of data catalogs and Master Data Management (MDM) tools and how the additional layer of Semantics is required in order to truly see their value for enterprises looking to manage their data better.

Data catalogs are quickly becoming a core technology for large enterprises looking to manage their data better. Given the sheer scale of major companies, there will be perhaps thousands of data repositories, covering potentially billions of data sets. Researchers looking to use/reuse this data face significant challenges, not least of which is finding an individual dataset in the first place.
This is where data catalogs promise to help, bringing in data with key metadata into a centralized environment, akin to a “data supermarket,” to provide a one-stop shop to find the data needed. While there are many commercial providers of data catalog software in the marketplace, many companies choose to build their own systems specific to their needs.
Why are large enterprises using Data Catalogs?
Some data catalog systems will look to add a certain level of standardization and metadata to the data they are importing. For instance, normalizing “M/Male/Men/Boy” to “MALE” to provide more consistency across data from different sources. This is more complex than it seems: What are the rules for this change (for instance, does “Boy”=“Man”)?;
Who maintains these rules? Should they be applied to all data? Should they be applied to all data? Should the original data be changed, or are copies made? This becomes even more complex when large numbers of diverse data are added to the catalog. Indeed, it is essential to note that the role of a data catalog is not to extensively enrich and manipulate the incoming data – that could have downstream consequences if users are looking for “the original data,” for instance, for regulatory submission. Nevertheless, data catalogs are rightly seen as a key foundation for many data science activities within large enterprises.
In an ideal world, everyone would use precisely the same language to describe the same physical things. While such a world would be fantastic from a data processing perspective, it’d likely make life pretty boring! Nevertheless, organizations are faced with the challenge of implementing some standardization level in preference to complete chaos. For instance, whenever you buy something online, you’re almost always presented with a drop-down menu to select your country of residence (which will often be in alphabetical order, and I wonder how many companies make the majority of their income from customers in Afghanistan vs. those lower down the alphabet!).
e-Commerce sites do this so you don’t make a mistake in typing in your country, removing a potential error in the financial transaction and thus increasing the system’s efficiency. The same is true inside large companies, it is much better for everyone to use the same names or identifiers for compounds, countries, employees, suppliers, projects, and many more things (also known as “entities”) to generate more consistency in the data.
Data Catalogs vs. Master Data Management
Master Data Management (MDM) tools are often employed to address this critical need. These systems are generally thought of as repositories of the “ground truth” and serve this to multiple I.T. applications across the enterprise. Many MDM systems go beyond this and allow the construction of reference models and data flow pipelines to understand the complex relationship between different data systems. In recent years, the line between data catalogs and master data management has become blurred, with many companies offering solutions that encompass both.
Using Data Standards vs. Semantic Enrichment
While data standardization is good, it still needs more depth of information required to power the latest generation of analytics and answer business questions. For instance, let’s say we standardized all different ways of writing about the humble mouse, mapping words such as “Mice,” “Mouse model,” “M. Musculus,” and so on to a common term “MOUSE.”
That does start to achieve some form of standardization, but we cannot go beyond basic Boolean search. For instance, many users may want to search for data on “any rodent.” While the data is there, the computer does not understand that a “MOUSE” is a rodent, as are rats, Guinea pigs, and other critical experimental models. Fundamental data retrieval for things like “all kinases,” “all pyrimidine compounds,” and “all anti-inflammatories” are not solved by standardization, to address these, we need semantics.
Representing relationships with ontologies
Representing the relationships between entities is the core function of an ontology. Ontologies such as Uberon represent the relationships between body organs and tissues, the BioAssay Ontology represents key parts of drug discovery, and the Gene Ontology represents a deep understanding of cellular processes.
Together with many other cornerstones, ontologies help bridge the gap between humans and machines. Indeed, many studies demonstrate the synergistic power of two key pillars of Artificial Intelligence, namely semantics and deep learning, to answer very complex scientific and medical questions. Watch our webinar on scaling the data mountain with Ontologies, Deep Learning, and FAIR to learn more.
While many organizations understand the power of ontologies, they have struggled in some situations due to the lack of highly tuned tools designed to maintain them. Many ontology solutions have suffered from:
- Authoritarian models – Built with the idea there is a central person(s) responsible for maintaining ontologies with complex change management processes required to make any modification. Such a model no longer fits today’s rapidly evolving science where researchers “at the coal face” are the best place to advise on the evolution of ontologies
- Poor UX (User-experience) – Anyone but an expert struggles to understand and use the system
- Not understanding the open environment – Many key life science ontologies originate and evolve outside of the company firewall. Systems must be designed to reconcile constant flux both internally and externally to stay up to date
For these reasons we created SciBite’s ontology management platform CENtree – a 21st-century resource designed specifically for life-science enterprises and employing a unique Artificial Intelligence (AI) engine to assist ontology management. For more information on CENtree, download the datasheet or watch our webinar on mastering enterprise-level ontologies for people and applications.
Fitting the pieces together – Data standards, semantic enrichment, and ontologies
Having described three critical pieces of enterprise reference data management, one may wonder how they fit together. As described above, we’re seeing the merging of master data management and data cataloging tools, though the key functions of the two remain quite different. But a key question concerns the role of semantics and where/how should semantic technologies be deployed within this stack? There is no ‘right’ answer here, and every organization will have its own architecture and needs. However, there are two generic models which are likely the most prevalent.
1. Enhancing Data Catalogues with Built-in Semantics
An obvious starting point would be to integrate semantic enrichment technology within your data catalog. The advantage is that the catalog itself becomes much more accessible to your users, through semantics, they can now ask questions such as “return data on any kinase” and others outlined above. Such an architecture could look like the following.
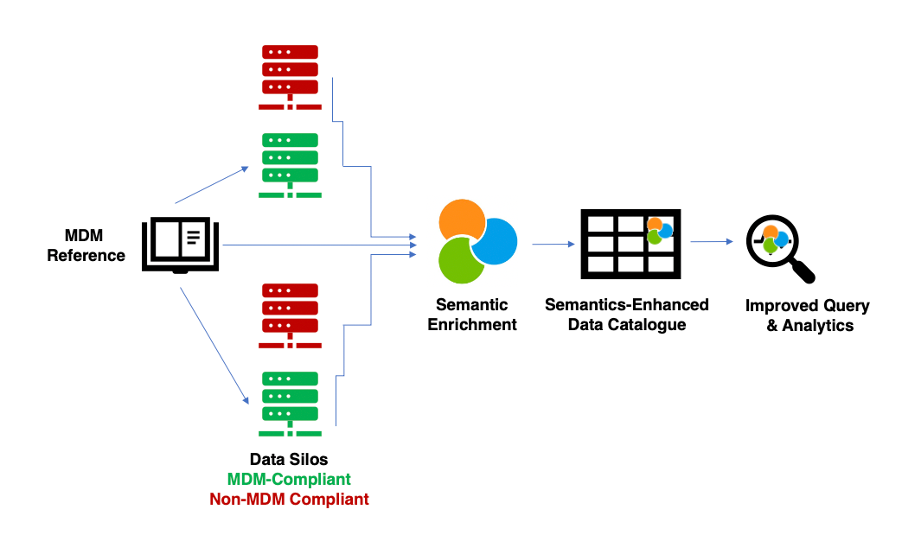
Here we have a mix of data sources, some of which are compliant with the company’s MDM reference data and some which are not. SciBite’s technologies are able to take the MDM references and ensure these are applied across the entire data catalog, building in a much greater degree of standardization. However, the benefits go further, as query and analytical tools can leverage the power of ontologies to ask complex questions that invoke the meaning of data, far beyond traditional keyword-based searches. A good example of such an implementation is at Pfizer and AstraZeneca, which use SciBite’s award-winning technology to build intelligent data catalogs.
Read more about the pivotal role of Semantic Enrichment in the evolution of Data Commons at Pfizer.
2. Adding semantic enrichment at the knowledge graph phase
The first approach is one we’ve seen employed by a number of our customers, but it doesn’t fit all use cases. Where there are very large data catalogs spanning vast data resources across all aspects of global enterprises, semantic enrichment can be instrumental to help narrow down searches to specific classes of data. However, it can also be overkill to label billions of data points in a large data catalog that may never be of interest. Thus, a second model is a “just-in-time” approach where data is enriched with semantics once it has been selected for downstream processing. The architecture here is a little different:

Here we rely on the standard data catalog flow, but once data have been selected, the application of ontologies over data and associated metadata allows for the creation of much richer knowledge graphs. We have seen such workflows work in several customer use cases and have previously outlined why this approach of knowledge graphs and semantics is so powerful.
Rapid, departmental, semantically enriched Data Catalogs
When one thinks of data catalogs, the image of a large infrastructure spanning all parts of an enterprise probably comes to mind. Indeed, any web search for the phrase will return a myriad of companies providing their view on how large organizations can benefit from bringing together data across the company. However, we’ve also seen a need for more “local” data catalogs, perhaps just on a departmental basis, that don’t need to be exposed companywide but require more nuanced tailoring to individual group needs.
Many of our customers employ our DOCstore semantic search engine technology to address these “Data Catalog-lite” uses cases. For instance:
- Creating a catalog of bioassay data from a range of internal and external sources. You can learn more in our use case on data cleansing to unlock the potential of Bioassay data.
- Creating a composite view of clinical trial information from public and commercial clinical trial repositories (as shown in the image below)
- Bringing together key elements from different types of documents within the same department. Read more in our use case on unlocking the full potential of departmental scientific documents.
Creating a database of entity-entity relationships (drug->adverse event, gene->phenotype) data for use cases such as pharmacovigilance and drug repurposing. Check out our use case on a modern, cost-effective approach to Pharmacovigilance
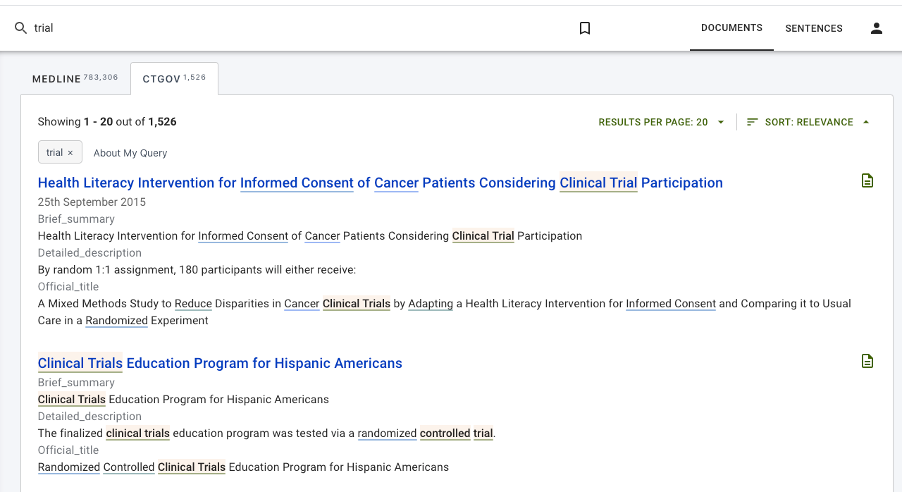
As an instance of DOCstore can be set up in minutes, our customers can create quick prototypes to demonstrate the utility of semantically enriched data portals. Often the prototype matures into the end solution but sometimes is simply the starting point for demonstrating how future tools should evolve. Because DOCstore is designed to implicitly understand data semantics, it can be a powerful mechanism to expose company data and deliver on the FAIR (Findable, Accessible, Interoperable, Reusable) mantra so crucial to today’s life science IT infrastructure.
Conclusion
Data Catalogs and Master Data Management tools provide a critical and foundational data infrastructure within any large corporation. However, additional layers are required to see the value of such an investment truly. Semantics represents such a critical addition, providing a mechanism for using the data in real-world scenarios. SciBite’s API-first, integration-centric software is designed to enable semantics within these environments, be they enterprise-wide or small department-specific installations.
If your organization is looking to improve its data management, whether you’re a large organization in need of enterprise-level technology or simply on a departmental basis, semantic enrichment technology like SciBite’s is key in ultimately producing machine-readable data to help you power the latest in technological advances.
Contact the SciBite team to discuss or find out more about how we can help you get more from your data, or watch our Introduction to Ontologies webinar.
Related articles
-

How semantic enrichment technology is changing the way we search
In our latest blog we discuss the challenges life sciences companies, like LifeArc, face in keeping up-to-date with scientific literature, and how semantic enrichment technology can automate this process to reduce the time spent mining data by up to 80%.
Read -

How ontology enrichment is essential in maintaining clean data
Ontologies have become a key piece of infrastructure for organisations as they look to manage their metadata to improve the reusability and findability of their data. This is the final blog in our blog series 'Ontologies with SciBite'. Follow the blog series to learn how we've addressed the challenges associated with both consuming and developing ontologies.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.