How the use of Machine Learning can augment adverse event detection
When it comes to identifying adverse events (AEs), things are not always as they seem. Consider a paper describing a new treatment for a given illness - how can we determine which adverse event terms refer to actual adverse events as opposed to symptoms of the illness itself, given that those terms may be identical? Is this new drug treating arrhythmias or causing them, for example?
Some entity types, such as adverse events, lean heavily on their context to be accurately identified. A human reading this paper from start to finish would be able to use their background knowledge about the drug and illness in question, as well as all the information they have read within the paper, to cast a judgment as to whether the term in question refers to an adverse event, a symptom or even the disease being treated.
We set out to see if machine learning could help our rules-based approach to make these kind of intelligent judgements.
Using Semantic Enrichment technology to add context
We can attempt to recreate the judgement of a human reading an article using defined rules. Indeed, SciBite’s named entity recognition (NER) engine TERMite, does exactly this using an array of methods including, for example, using ‘booster’ terms to say: if this term is used in close proximity to the phrase in question, it is more likely that said phrase is of a specific type. So if we see the term ‘hedgehog’ surrounded by biomolecular terms, we’re probably talking about the genetic pathway. If we see the same word surrounded by ecological terms, we’re probably talking about the prickly animal which you shouldn’t feed milk.
Using a layer of Machine Learning to add further enriched context
Natural language is deeply complex, and each and every paper has its own unique grammatical structures. Rules can take us so far, but there will always be edge cases, and we can’t create rules for each and every one of them. This is where we aim to use machine learning (ML) to provide a layer of contextual analysis to help verify TERMite results in ambiguous settings. As opposed to explicitly defined rules, ML methods are able to notice patterns in noisy data. This emphasis on pattern recognition enables ML methods to make correct decisions in novel situations by observing deeper, more abstract similarities in structure.
Putting the logic to the test with a Neural Network
To test this with adverse events, we trained a neural network (with an LSTM-CRF architecture) on manually curated drug label data from a competition hosted at the Text Analysis Conference (TAC) 2017. This form of neural network is able to iterate through sequential data and use ‘memories’ from previous steps to inform decisions about the current step. This allows it to use contextual information found throughout a text to decide whether the current section it is looking at does indeed contain an adverse event.
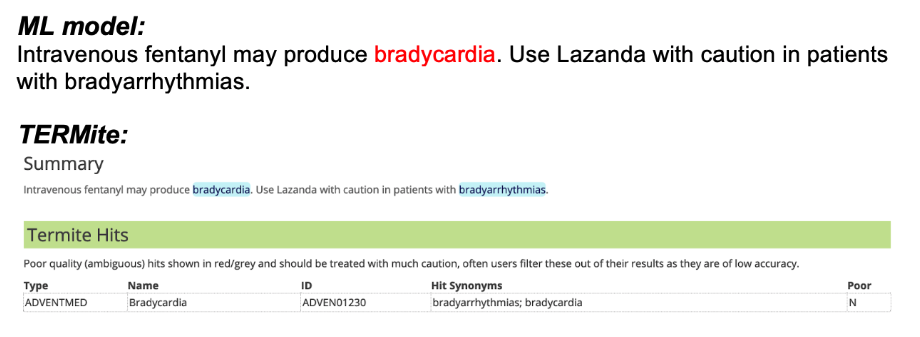
The neural network performed strongly on the TAC2017 adverse events dataset with some notable differences when compared to pure TERMite annotations. Figure 1 illustrates the most useful of these differences. In (a), we can see that TERMite has correctly identified both bradycardia and bradyarrhythmias as strings containing terms that are matched by our adverse event dictionary. Conversely, the second sentence is an instruction regarding the use of the drug Lazanda in patients with an existing symptom, and not an assertion that the drug causes said symptom.
One approach is to add manually defined rules to filter possible AE hits based on their surrounding context. However, the aim here was to determine where machine learning could add additional value and we can see that the neural network has correctly made this differentiation without the need for pre-defined rules.
Likewise in (b), the neural network has recognised that ‘liver function disorders’ refers to a pre-existing condition, and not to an adverse event caused by the medication.
(a)
(b)

Figure 1. AE hits from the ML model as well as TERMite (a) TERMite identifies bradyarrhythmias and (b) liver function disorders as AEs. In these particular contexts, the strings refer to disease states that should be considered during the administration of the drug of interest and not to AEs observed as a result of taking the drug
Although TERMite has correctly identified the entities of interest in general terms, in the specific context of drug labels, the ML model introduces an extra layer of refinement. We might then use the input from the ML model to flag low confidence hits based on the type of data being sent to TERMite (see Figure 2). In other words, we could inject different neural networks into the TERMite workflow for extracting hits in patents, drug labels, articles and so on. We can even apply this approach to patient forum data, where adverse events are often described using a vast array of colloquial phrases which have recently been aligned to our adverse events VOCab by our ontologies team!
The value of combining Machine Learning with Named Entity Recognition
The major bottleneck for machine learning is the availability of training data, and this is evidenced in some of the mistakes made by the model shown in Figure 3. These include characters being missed as well as terms being flagged which are simply incorrect because they seem to follow a similar pattern to other adverse events. Thankfully, just as machine learning can be used to augment TERMite, so too TERMite can be used to augment machine learning by sanity checking these kinds of mistakes.
Furthermore, even if the ML detection was perfect, TERMite would be invaluable in normalising entity synonyms to unique identifiers, as is often required for reporting adverse events to regulatory bodies. Our adverse event vocabulary maps terms back to MedDRA, for example. These IDs can then be connected back into knowledge graphs or other structured data sources to perform cascades of analysis starting from simple, unlabeled text. Take a look at Figure 4 for some examples of synonyms successfully detected as adverse events by our ML model, and how TERMite maps them to the same identifier.

Figure 2. Using ML to flag low confidence hits. Through integrating TERMite annotations with ML output we can flag potentially ambiguous AEs.

Figure 3. ML limitations. Some of the problems of the ML approach are highlighted above.
Using SciBite’s semantic technologies to enhance and support Machine Learning models
As mentioned earlier, at present, there is insufficient public data available to train ML models that are reliable across various edge cases due to the time investment required to curate these datasets. SciBite’s semantic technologies can be used to streamline the curation process. For example, by marking up an entire corpus (whether that be Medline, drug labels or even patient forum data) with the adverse event VOCab, one can quickly identify all sentences that mention adverse events, whether that be in the correct context or not. By serving this subset of sentences to expert curators, positive and negative datasets can be produced and used directly to train ML models. We have applied this process to various settings here at SciBite including the more complex task of identifying relations, such as protein-protein interactions, from the literature.
(a)

(b)

Figure 4. TERMite normalisation (a) and (b) show examples of strings that are identified as adverse events by the ML model and how TERMite aligns these to unique identifiers in a process of normalisation, enabling a plethora of downstream analyses
Our vision at SciBite is not to throw out established methods and replace them with ML models, but to combine the deep pattern recognition of machine learning with the reliability of human knowledge captured in curated ontologies. Driverless vehicles provide an interesting parallel: although much of the hype has been around their use of deep learning, the reality is that these systems rely heavily on human-curated decision trees to ensure they are as safe as possible.
SciBite’s semantic technologies can not only be used in the production of accurate ML models, but can also benefit from them. Here we have described one such area of application, augmenting ML to enable a more context-aware TERMite in the realm of adverse events.
Get in touch with the team for more details on how TERMite can be utilised for adverse event detection.
You can also download our use case on ‘A Modern, Cost-effective Approach to Pharmacovigilance‘ to learn more.
Related articles
-
GSK Japan selects semantic platform to enhance pharmacovigilance capabilities
SciBite today announced that GSK Japan, one of Japan’s leading research-based pharmaceutical and healthcare companies, has selected SciBite’s Semantic Platform to enhance pharmacovigilance capabilities and deliver on its commitment to improve the quality of human life.
Read -
Are ontologies relevant in a machine learning-centric world?
SciBite CSO and Founder Lee Harland shares his views on why ontologies are relevant in a machine learning-centric world and are essential to help "clean up" scientific data in the Life Sciences industry.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.