Bringing FAIR data and CMC procedures together
In this blog we introduce our new package of vocabularies designed to enable the FAIR data principles and help pharmaceutical companies navigate their documents with respect to Chemistry, Manufacture and Control (CMC) procedures.
The vast majority of people have, at some stage in their life, had to rely on medication of one type or another. What is not apparent to most, however, is the sheer extent of procedures and testing that drug has gone through to make it to market.
Aside from the initial discovery of a therapeutic chemical or biologic and the subsequent clinical trials that are required to ensure it is safe and effective for a particular health condition, there are numerous other requirements that a new drug has to achieve in order for the final drug product to be licensed and approved for manufacture and marketing. The collective name for these procedures is Chemistry, Manufacture and Control, or CMC.
Do sweat the small stuff – Importance of effectively tracking the CMC progress
CMC procedures are enforced by regulators such as the Food and Drug Administration (FDA) and the European Medicines Agency (EMA) and are essential to ensure that the performance of a drug observed in clinical trials is stable and consistent when the drug product formulation is scaled up during commercial production. CMC includes the more technical assays for physicochemical properties, such as stability, solubility and particle size distribution, which can affect bioavailability of the drug, but also includes the formulation of a drug, e.g. coated tablet or transdermal patch, and even the colour of the drug substance or how the drug is packaged, which can affect it’s shelf life.
With so many different types of requirements to fulfil, pharmaceutical companies soon accumulate a vast collection of reports, forms and general paperwork that document each of the procedures applied to a drug substance. The need for a fast and effective method of tracking the progress of each of their products through the CMC process is essential to avoid delays in delivering the drug to patients.
Variations on a theme – Dealing with terminology ambiguity
It should be easy to search through a collection of documents for a piece of information, right? The answer may be ‘Yes’, if you want only the one answer and you know exactly which words to search for.
Let’s imagine, however, you need to find all the dosage forms of a particular drug product that you’re interested in. You would need to first determine all possible ways in which the drug product had been referred to in the documents you are searching. This in itself is likely to be a time-consuming task. Take, for example, the common pain relief medicine, Acetaminophen. This alone has over 150 different names, not including each manufacturer’s internal codes and identifiers. Add also the potential of spelling mistakes (a high possibility in internal documents and memos) and variations in word order and suddenly you are looking at hundreds, possibly thousands, of different variations to refer to a single drug.
If we now think about searching dosage forms and all the variations in terminology for these, we can see that this simple query is very quickly turning into a complex task. Dosage forms are the ways in which a drug is formulated for administration to the patient, so it could be a tablet, capsule or intravenous solution, for example. An additional problem with the dosage form terminology is that some of the terms are incredibly general, for example “film” or “oral”, which could refer to countless other concepts not related to drug formulation. We now begin to see that context is also an essential consideration when searching for keywords in documents.
Take these two sentences that match a simple text search for acetaminophen or one of its synonyms, paracetamol, and ‘oral’:
- “NSAID use (but not paracetamol use) was associated with a reduced risk of oral cancer”
- “Randomized controlled trials comparing IV and oral dosage forms of acetaminophen were included”
Both meet the criteria for the search, but the context in which the drug name appears is very different. Only the second sentence is referring to the dosage form of the drug, the first sentence uses ‘oral’ in the wrong context for our purposes.
The SciBite solution to tracking CMC documentation
The principle of FAIR (Findable, Accessible, Interoperable, Reusable) data is that users should be able to effectively find and re-use corporate data. Thus, reducing the variances described above is key. In order to combine context with the many variations of the concepts involved, SciBite are building master vocabularies encompassing terminology used in the CMC field.
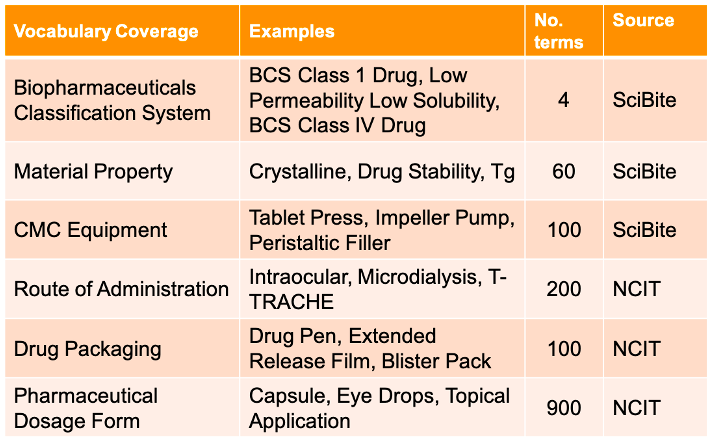
Table 1. SciBite’s new vocabularies covering CMC-related procedures. The Source column indicates the original source of the terms in that vocabulary: SciBite = custom-made terms, NCIT = National Cancer Institute Thesaurus [1].
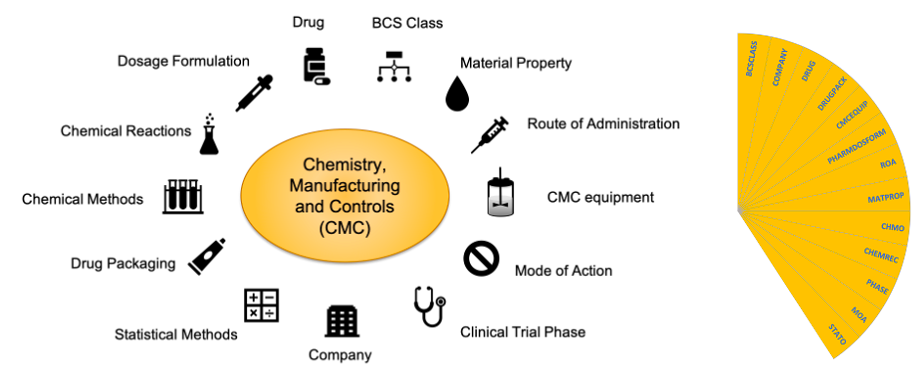
Figure 1. The SciBite CMC pack. The CMC pack contains the following vocabularies: Biopharmaceuticals Classification System (BCSCLASS), Company (COMPANY), Drug (DRUG), Drug Packaging (DRUGPACK), CMC-related equipment (CMCEQUIP), Pharmaceutical Dosage Formulation (PHARMDOSFORME), Route of Administration (ROA), Material Property (MATPROP), Chemical Methods (CHMO), Chemical Reactions (CHEMREC), Clinical Phase (PHASE), Mechanism of Action (MOA), Statistical Methods (STATO).
This set will form a new CMC package (Figure 1) that can be used by customers to mine information from their internal documents and ELNs or incorporate into electronic data capture systems to ensure consistency at data entry point.
Learn more in our Webinar on scaling the data mountain with ontologies, deep learning & FAIR.
We have also worked with customers to prepare custom dictionaries containing their proprietary codes and identifiers for their portfolio of drug compounds, including intermediate chemicals and impurities. When used alongside the CMC package of vocabularies, this allows for more sophisticated and thorough text querying. If we go back to our original example of searching for all the formulations of a particular drug product, this would mean the capability to include internal drug codes and identifiers in the query, allowing for comprehensive and fast searching of internal documents and memos.
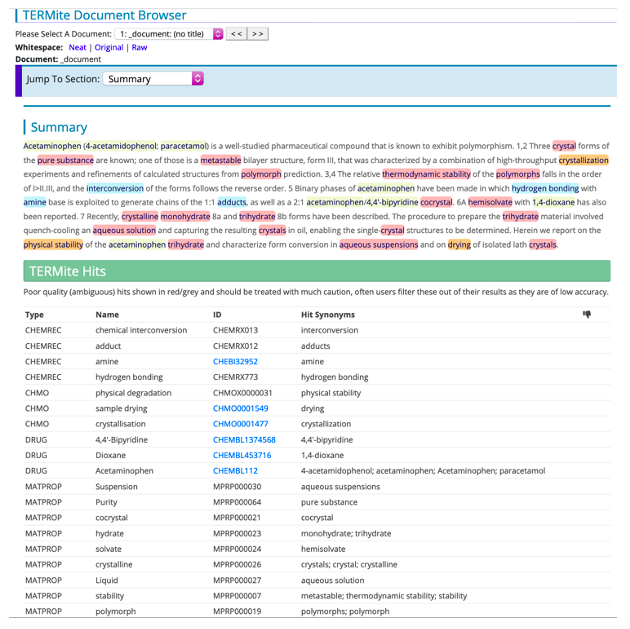
Figure 2. Identifying CMC terminology in text. The CMC vocabularies can be used to identify CMC-related content in documents. Here the CHEMREC, CHMO, DRUG and MATPROP vocabularies have been used in SciBite’s named entity recognition tool TERMite to highlight matching terms in an article [2].
By working closely with our customers, we are able to tailor SciBite technologies to their specific needs, delivering bespoke solutions to their data management requirements and helping to make their data FAIR.
If you would like to discuss your specific requirements around CMC, please contact the SciBite team.
Related articles
-

Why do you need FAIR data?


For many organizations, the idea of adopting FAIR can be confusing and daunting. Over the coming weeks, we’ll present a series of blogs to help demystify FAIR. In this series, we’ll cover topics including how ontologies provide the key to being FAIR, and how FAIR enables you to get more value from your data.
Read -

The key to being FAIR
In our previous blog, we explained why FAIR data is important not only for biotech and pharmaceutical companies but also for their partners. Here we describe how ontologies are the key to having the richly described metadata that is at the heart of making data FAIR. Let’s explore how ontologies help with each aspect of the FAIR data principles…
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.