Are ontologies relevant in a machine learning-centric world?
SciBite CSO and Founder Lee Harland shares his views on why ontologies are relevant in a machine learning-centric world and are essential to help "clean up" scientific data in the Life Sciences industry.
Last week was a busy week for SciBite! Along with our first-ever US-based SciBite User Group Meeting, we attended the Pistoia Artificial Intelligence (AI) / Machine Learning (ML) workshop and annual conference.
The workshop featured a number of interesting presentations from both consumers and producers of AI/ML tools. While this covered a range of different use cases within the industry (focusing on the well-established areas of image recognition and genomics analysis), there was one clear message that came through time and time again…
While many within the industry are subject to the hype associated with AI/ML, it is not a magic bullet and it can’t work without proper scientific rigor. There was almost unanimous agreement that simply throwing the technique at a bucket of bad-quality data and hoping “it’ll just work” was not the way forward and betrays the fundamental principles of science.
“Cleaning up” scientific data with ontologies
Much of the discussions in the meetings and over coffee focused on how to generate “clean” data, what that actually meant, and its relevance to prominent issues such as experimental reproducibility that are very pertinent right now.
This discussion brings us to a common question we often ask as we travel the world talking to potential customers and collaborators, ‘Are ontologies relevant in a machine learning-centric world? Can’t the AI just do it all?’ In fact, if SciBite is an “ontology company” at heart, why do we need SciBite? As most data scientists will know, it is within standard practice to be able to train an algorithm to recognize different concept types, such as identifying potential adverse events (although this sometimes leads to bizarre consequences!).
However, this misses the key contribution that ontologies make – identifying what is known, in the context of an existing scientific framework. By annotating content with, say, the MedDRA ontology, we know these concepts are adverse events, not just predictions of something that might be. While this may be obvious, in the past, ontology-based annotation was actually quite hard to achieve, both in a technical sense (finding software that could perform at scale using REST) and a linguistic one. To learn more, watch our Introduction to Ontologies webinar.
Using Ontology-based text annotation for data cleansing and pre-processing
The work we have done to deliver ontology-based text annotation as a simple, scalable service is now a critical component in data preprocessing/cleansing for many pharma companies.
But in a practical sense, what does this actually mean – how do ontologies make machine learning better? Let’s take the example of the gene “Insulin-Like Growth Factor Binding Protein Acid Labile Subunit.” That’s quite a lengthy and definitely unambiguous name, so you’ll see it referred to as IGFALS quite often.
If you look at this genes official synonym list, you can clearly see it’s also referred to as “ALS”. Within common biomedical discourse, ALS is used almost entirely as an abbreviation for the disease, Amyotrophic lateral sclerosis, but sometimes it doesn’t and it means this insulin-related gene.
Thus, there is a conflict as to what ALS actually means. Thus, if we just “leave it to the computer,” we may find that the machine learning for the disease ALS, also mistakenly incorporates literature for IGFALS, giving an incorrect link between ALS and insulin signaling with potentially dangerous consequences for any generated model.
We see this with many more entities, such as MAP3K8, important cancer/growth protein that is also known as “cot.” A quick search of PubMed shows that the vast majority of the uses of the word “cot” in the literature are nothing to do with this protein. Perhaps the most famous gene example is BRCA1, the well-known breast-cancer protein, which has an official synonym of “IRIS,” which is, of course, part of the eye.
Conversely, we also have a situation where multiple terms may be used for the same thing, with almost similar frequencies (e.g., Tylenol vs. Paracetamol or Viagra vs. Sildenafil). If the data concerning one of these terms is more skewed (e.g., “Tylenol” is more often used in the USA), then the models themselves will be biased and unreliable. Read our blog to discover how the semantic approach to using ontologies is essential in successfully training machine learning data sets.
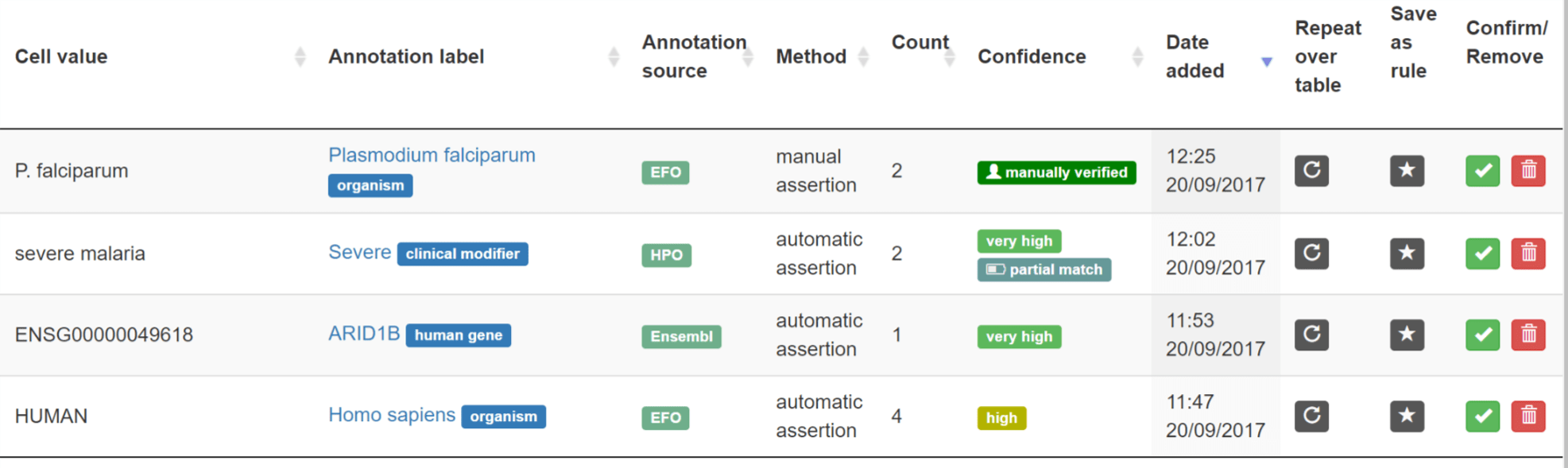
The image above shows how SciBite transforms plain text in experimental data (left-hand columns) into unambiguous ontology-concepts (on the right). In turn, this annotation powers more robust and reproducible experimental analysis and machine learning.
The competitive advantage of ontology-based data cleansing
At SciBite, we routinely use ontology-based data cleansing as a pre-processing step in our machine learning activities and have extensive evidence as to the value of this in critical real-world pharma use cases. By performing this step, instead of plain text entering into machine learning models, we supply concept identifiers, which the algorithms can use to generate more reliable models by uniting different terms and eliminating the ambiguity of human language.
In turn, this aids reproducibility within in silico-based experiments, which was a further significant topic of debate at the Pistoia meeting. So, back to our question, “Are ontologies still relevant”? Hopefully, this post demonstrates the essential contribution ontologies make when using text-based data within ML/AI activities. It was very clear from the Pistoia meeting that data scientists are deeply concerned with the quality of data going into their models and so solutions to tackle this issue are very much required.
All in all, this was a great meeting, with some fantastic insights into how pharma is using ML/AI, and we’re looking forward to being part of this community going forward.
Watch our Webinar on scaling the data mountain with Ontologies, Deep Learning & FAIR or read our Ontology Management whitepaper to learn more about our ontology-led solutions and how they can help unlock the potential of scientific data in your business.
Get in touch with the team today if you’d like to discuss further.
Related articles
-

Semantic approach to training ML data sets using ontologies & not Sherlock Holmes
In this blog we discusses how Sherlock Holmes (amongst others) made an appearance when we looked to exploit the efforts of Wikipedia to identify articles relevant to the life science domain for a language model project.
Read -

A helping hand from BERT for Deep Learning approaches
SciBite CSO and Founder Lee Harland shares his views on the use of BERT (or more specifically BioBERT) for deep learning approaches.
Read
How could the SciBite semantic platform help you?
Get in touch with us to find out how we can transform your data
© Copyright © 2024 Elsevier Ltd., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies.